
| |
auteur :
Ioan Calapodescu | Architecture d'une application utilisant DOM :
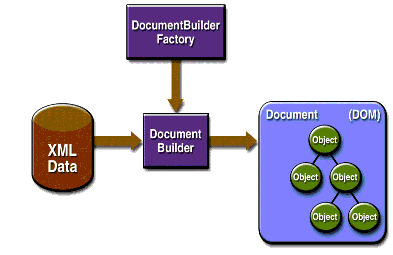 Source image : J2EE 1.4 Tutorial Pour commencer, l'application récupère un constructeur de documents (javax.xml.parsers.DocumentBuilder) à partir d'une fabrique de constructeurs (javax.xml.parsers.DocumentBuilderFactory).
C'est ce constructeur de documents qui va construire le DOM ou document (org.w3c.Document) à partir de la source XML.
Le Document est la représentation, sous forme d'arbre "d'objets", des données contenues dans le XML.
|
lien : Comment ouvrir un fichier XML avec DOM ?
lien : Quelles autres API existent pour travailler avec XML ?
|
| |
auteur :
Ioan Calapodescu | Voici un exemple, qui montre comment ouvrir un fichier XML avec l'API DOM :
import javax.xml.parsers.*;
import org.w3c.dom.*;
import org.xml.sax.*;
import java.io.*;
public class ExempleDOM{
public static void main(String[] args){
try{
DocumentBuilderFactory fabrique = DocumentBuilderFactory.newInstance();
DocumentBuilder constructeur = fabrique.newDocumentBuilder();
File xml = new File("ExempleDOM.xml");
Document document = constructeur.parse(xml);
}catch(ParserConfigurationException pce){
System.out.println("Erreur de configuration du parseur DOM");
System.out.println("lors de l'appel à fabrique.newDocumentBuilder();");
}catch(SAXException se){
System.out.println("Erreur lors du parsing du document");
System.out.println("lors de l'appel à construteur.parse(xml)");
}catch(IOException ioe){
System.out.println("Erreur d'entrée/sortie");
System.out.println("lors de l'appel à construteur.parse(xml)");
}
}
}
Vous pouvez télécharger un exemple simple (affichage sur la sortie standard du DOM) ci-dessous.
|
lien : Comment parcourir l'arborescence d'un DOM ?
téléchargement : ExempleDOM.zip
|
| |
auteur :
Ioan Calapodescu | Tout comme pour SAX, on peut gérer les erreurs lors de la construction d'un Document grâce à un ErrorHandler.
Par exemple :
public class GestionnaireDErreurs implements ErrorHandler{
protected String message(SAXParseException e){
String message = "Message : "+e.getMessage()+"\n";
message += "Ligne "+e.getLineNumber()+", colonne "+e.getColumnNumber()+"\n";
message += "Public id : "+e.getPublicId()+"\n";
message += "System id : "+e.getSystemId();
return message;
}
protected void printSAXException(SAXParseException e){
System.out.println(message(e));
if(e.getException() != null){
e.getException().printStackTrace();
}
}
public void warning(SAXParseException exception) throws SAXException{
System.out.println("*** Warning ***");
printSAXException(exception);
}
public void error(SAXParseException exception) throws SAXException{
System.out.println("*** Erreur ***");
printSAXException(exception);
}
public void fatalError(SAXParseException exception) throws SAXException{
String message = "*** Erreur fatale ***\n";
message += message(exception);
SAXException se = new SAXException(message, exception);
throw se;
}
}
Exemple d'utilisation :
DocumentBuilderFactory fabrique = DocumentBuilderFactory.newInstance();
DocumentBuilder constructeur = fabrique.newDocumentBuilder();
constructeurs.setErrorHandler(new GestionnaireDErreurs());
Document document = constructeur.parse(new File("ExempleDOM.xml"));
|
lien : Comment gérer les erreurs durant le parsing ?
|
| |
auteur :
Ioan Calapodescu | Vous pouvez obtenir de nombreuses informations sur un document XML à partir d'une instance de org.w3c.dom.Document.
Voici un exemple récupérant, à partir d'un Document, des informations générales, des informations sur le type de document et sur la configuration DOM :
public static void printDOMInfos(Document document){
System.out.println("INFORMATIONS GENERALES");
String uri = document.getDocumentURI();
System.out.println("URI = "+uri);
String xVersion = document.getXmlVersion();
System.out.println("Version XML = "+xVersion);
String xEncoding = document.getXmlEncoding();
System.out.println("XML encoding = "+xEncoding);
String iEncoding = document.getInputEncoding();
System.out.println("Input encoding = "+iEncoding);
boolean standalone = document.getXmlStandalone();
System.out.println("XML standalone = "+standalone);
boolean strictError = document.getStrictErrorChecking();
System.out.println("Strict error checking = "+strictError+"\n");
System.out.println("DOCTYPE");
printDoctype(document.getDoctype());
System.out.println("CONFIGURATION");
printDOMConfiguration(document.getDomConfig());
}
Pour le détail des méthodes printDoctype et printDOMConfiguration, téléchargez le fichier ci-dessous.
|
téléchargement : InfosDOM.zip
|
| |
auteur :
Ioan Calapodescu | Avant de commencer à parcourir un arbre DOM et à en extraire les données, il est nécessaire de bien comprendre sa structure. Il est notamment nécessaire de bien faire la distinction entre les différents types de nodes. Une erreur couramment commise est le fait de confondre Node et Element.
- Node (org.w3c.dom.Node) : Un Node (ou noeud) est l'unité de base de l'arbre. Cela peut être du texte, un élément, une portion CDATA ou encore une instruction. Pour connaître le type d'un Node utilisez la méthode getNodeType().
- Element (org.w3c.dom.Element) : L'interface Element définit un élément au sens XML (XHTML ou HTML). Un élément est constitué d'un tag, d'attributs et d'un contenu (autres nodes et éléments).
Voici les différents types de nodes et le résultat des méthodes capables d'en découvrir le contenu.
| Interface (org.w3c.dom) |
getNodeType() (short) |
getNodeName() (String) |
getNodeValue() (String) |
getAttributes() (NamedNodeMap) |
| Attr |
ATTRIBUTE_NODE |
Le nom de l'attribut. |
La valeur de l'attribut. |
null |
| CDATASection |
CDATA_SECTION_NODE |
"#cdata-section" |
Le contenu de la section CDATA. |
null |
| Comment |
COMMENT_NODE |
"#comment" |
Le contenu du commentaire. |
null |
| Document |
DOCUMENT_NODE |
"#document" |
null |
null |
| DocumentFragment |
DOCUMENT_FRAGMENT_NODE |
"#document-fragment" |
null |
null |
| DocumentType |
DOCUMENT_TYPE_NODE |
Le nom du type. |
null |
null |
| Element |
ELEMENT_NODE |
Le nom du tag. |
null |
Les attributs de l'élément. |
| Entity |
ENTITY_NODE |
Le nom de l'entité. |
null |
null |
| EntityReference |
ENTITY_REFERENCE_NODE |
Le nom de l'entité réferencée. |
null |
null |
| Notation |
NOTATION_NODE |
Le nom de la notation. |
null |
null |
| ProcessingInstruction |
PROCESSING_INSTRUCTION_NODE |
La cible de l'instruction. |
Les données de l'instruction. |
null |
| Text |
TEXT_NODE |
"#text" |
Le texte en lui-même. |
null |
Si vous voulez récupérer le texte contenu dans un node (et dans l'ensemble de ses enfants), utilisez la méthode getTextContent().
|
lien : Comment parcourir l'arborescence d'un DOM ?
lien : Comment accèder au contenu et aux attributs d'un Element ?
|
| |
auteur :
Ioan Calapodescu | La première chose à faire pour commencer à parcourir votre arbre DOM est de récupérer la racine.
Document document = ...;
Element racine = document.getDocumentElement();
A partir de cette racine, vous pouvez parcourir l'enseble du document. Voici les méthodes à utiliser :
Méthodes de l'interface Node
- getChildNodes : retourne une NodeList contenant l'ensemble des nodes enfants.
- getFirstChild : retourne le premier Node enfant.
- getLastChild : retourne le dernier Node enfant.
- getNextSibling : retourne la prochaine occurrence du Node.
- getParentNode : retourne le noeud parent du Node.
- getPreviousSibling: retourne la précédente occurrence du Node.
Méthodes de l'interface Element
- getElementsByTagName : retourne une NodeList contenant les éléments enfants dont le tag correspond au nom passé en paramètre (* pour renvoyer tous les éléments).
- getElementsByTagNameNS : même chose que getElementByTagName, avec prise en compte des namespace.
|
| |
auteur :
Ioan Calapodescu | Pour accèder au contenu et aux attributs d'un Element, on peut utiliser les méthodes getTextContent et getAttributesByTagName.
Voici un exemple, dans lequel on extrait d'un XHTML les liens et leurs propriétés :
public static List<Element> getLinks(String xhtmlUrl) throws Exception{
List<Element> liens = new ArrayList<Element>();
InputStream stream = null;
try{
DocumentBuilderFactory fabrique = DocumentBuilderFactory.newInstance();
fabrique.setValidating(true);
DocumentBuilder constructeur = fabrique.newDocumentBuilder();
URL url = new URL(xhtmlUrl);
stream = url.openStream();
Document document = constructeur.parse(stream);
Element racine = document.getDocumentElement();
String tag = "a";
NodeList liste = racine.getElementsByTagName(tag);
for(int i=0; i<liste.getLength(); i++){
Element e = (Element)liste.item(i);
if(e.hasAttribute("href"))liens.add(e);
}
}catch(Exception e){
throw e;
}finally{
try{stream.close();}catch(Exception e){}
return liens;
}
}
Exemple d'utilisation :
String url = "http://www.w3.org/";
List<Element> liens = getLinks(url);
for(Element lien : liens){
String href = lien.getAttribute("href");
String texte = lien.getTextContent();
texte = (texte!=null)?texte:href;
System.out.println("Lien "+texte+" pointe sur "+href);
}
Vous pouvez télécharger cet exemple ci-dessous.
Pour avoir plus d'informations sur un Element (ou un attribut) définit par un schéma, utilisez la méthode getSchemaTypeInfo().
|
téléchargement : LiensXHTML.zip
|
| |
auteur :
Ioan Calapodescu | Cela dépend de ce que vous entendez par "enfant". Comme toujours, il faut bien faire la différence entre Node et Element.
Nombre d'enfants de type Node
Element e = ...;
NodeList enfants = e.getChildNodes();
int nombreDeNoeudsEnfants = enfants.getLength();
Nombre d'enfants de type Element
Element e = ...;
NodeList enfants = e.getElementsByTagName("*");
int nombreDElementsEnfants = enfants.getLength();
Cela méritait d'être souligné car l'erreur (la confusion entre Node et Element) est souvent commise.
|
lien : Qu'est ce que XPath ? Pourquoi l'utiliser ?
|
| |
auteur :
Ioan Calapodescu | L'API DOM fournit avec les classes Document, Node et ses dérivées (Element, par exemple) tout un ensemble de méthodes permettant la modification du document. Voici, en résumé, les méthodes disponibles pour Document, Node et Element :
Méthodes de Document
- adoptNode(Node source) : importe le noeud passé en paramètre. Si ce noeud appartient déjà à une arborescence, il en est supprimé. Le méthode retourne le noeud adopté ou null si l'opération échoue.
- importNode(Node importedNode, boolean deep) : importe, dans le document, le noeud passé en argument et ses enfants (si deep vaut true). Le noeud ainsi importé n'a pas de parent. Le noeud ainsi importé, contrairement à adoptNode, est une simple copie. Le noeud est retourné comme résultat.
- renameNode(Node n, String namespaceURI, String qualifiedName) : renomme le noeud passé en paramètre et retourne ce dernier. Attention, seuls les nodes de type item et Attr peuvent être ainsi renommés.
- setDocumentURI(String documentURI) : remplace l'URI du document.
- setXmlStandalone(boolean xmlStandalone) : définit si le XML est "standalone" ou non.
- setXmlVersion(String xmlVersion) : définit la version du XML ("1.0" par défaut).
- normalizeDocument() : cette méthode valide les modifications apportées au DOM. Voir aussi la méthode normalize() de l'interface Node.
Méthodes de Node
- appendChild(Node newChild) : ajoute le noeud passé en paramètre à la fin des autres enfants du node. cette méthode retourne le noeud ajouté.
- insertBefore(Node newChild, Node refChild) : insère "newChild" avant "refChild" et retourne "newChild".
- removeChild(Node oldChild) : supprimme le noeud passé en paramètre et le retourne.
- replaceChild(Node newChild, Node oldChild) : remplace oldChild par newChild et retourne oldChild.
- setNodeValue(String nodeValue) : met "nodeValue" comme valeur pour le noeud. Voir Quels sont les différents types de nodes ? pour connaître les valeurs possibles.
- setPrefix(String prefix) : met "prefix" comme nouveau préfixe du noeud.
- setTextContent(String textContent) : met "textContent" comme contenu du noeud. Attention, ceci supprimme l'ensemble des noeuds enfants.
Méthodes de Element
- removeAttribute(String name) : supprimme l'attribut nommé.
- setAttribute(String name, String value) : crée un nouvel attribut (ou modifie la valeur de l'attribut si il existe déjà).
- setIdAttribute(String name, boolean isId) : crée un nouvel attribut de type ID (ou modifie la valeur de l'attribut si il existe déjà).
Ces trois méthodes ont toutes des variantes. Les méthodes XXXNode permettent notamment de retourner l'instance de Attr modifiée ou supprimmée.
|
lien : Comment créer ou modifier un fichier XML avec DOM et XSLT ?
lien : Comment créer un DOM de toutes pièces?
lien : Quels sont les différents types de nodes ?
|
| |
auteur :
Ioan Calapodescu | La classe DocumentBuilder permet de créer une nouvelle instance de Document grâce à la méthode newDocument(). Pour le reste, Document fournit un ensemble de méthodes createXXX, qui vont vous permettre de créer des nodes, éléments, commentaires et attributs.
Voici un exemple :
DocumentBuilderFactory fabrique = DocumentBuilderFactory.newInstance();
DocumentBuilder constructeur = fabrique.newDocumentBuilder();
Document document = constructeur.newDocument();
document.setXmlVersion("1.0");
document.setXmlStandalone(true);
Element racine = document.createElement("annuaire");
racine.appendChild(document.createComment("Commentaire sous la racine"));
Element personne = document.createElement("personne");
personne.setAttribute("id","0");
racine.appendChild(personne);
Element nom = document.createElement("nom");
nom.setTextContent("un nom");
personne.appendChild(nom);
Element prenom = document.createElement("prenom");
prenom.setTextContent("un prénom");
personne.appendChild(prenom);
Element adresse = document.createElement("adresse");
adresse.setTextContent("une adresse");
personne.appendChild(adresse);
document.appendChild(racine);
Transformé en XML ce DOM donnerait :
<?xml version="1.0" encoding="ISO-8859-1"?>
<annuaire>
<personne id="0">
<nom>un nom</nom>
<prenom>un prénom</prenom>
<adresse>une adresse</adresse>
</personne>
</annuaire>
|
lien : Comment créer ou modifier un fichier XML avec DOM et XSLT ?
téléchargement : CreationDOM.zip
|
| |
auteur :
willowII |
Le bout de code suivant utilise la classe Transformer pour écrire un document DOM dans une String en passant par un StringWriter.
Document document = ...;
DOMSource domSource = new DOMSource(document);
StringWriter writer = new StringWriter();
StreamResult result = new StreamResult(writer);
TransformerFactory tf = TransformerFactory.newInstance();
Transformer transformer = tf.newTransformer();
transformer.transform(domSource, result);
String stringResult = writer.toString();
|
Consultez les autres F.A.Q's
Les codes sources présentés sur cette page sont libres de droits, et vous pouvez les utiliser à votre convenance. Pour le reste, ce document constitue une oeuvre intellectuelle protégée par les droits d'auteurs.
Ce document issu de http://www.developpez.com est soumis à deux licences, en fonction des contributeurs :
- Les contributions de Clément Cunin et Johann Heymes sont soumises aux termes de la la licence GNU FDL traduite en français ici. Permission vous est donnée de distribuer, modifier des copies des contributions de Clément Cunin et Johann Heymes tant que cette note apparaît clairement :
"Ce document issu de http://www.developpez.com est soumis à la licence GNU FDL traduite en français ici. Permission vous est donnée de distribuer, modifier des copies de cette page tant que cette note apparaît clairement".
- Pour ce qui est des autres contributions : Copyright © 2004 Developpez LLC : Tous droits réservés Developpez LLC. Aucune reproduction, ne peux en être faite sans l'autorisation expresse de Developpez LLC. Sinon vous encourez selon la loi jusqu'à 3 ans de prison et jusqu'à 300 000 E de dommages et intérêts. Cette page est déposée à la SACD.
|
|
|


